
Gemini 1.5 Pro has emerged as the new leader in AI benchmark rankings, outperforming prior records set by other leading AI models such as OpenAI’s ChatGPT-4o.

The Gemini 1.5 Pro experimental version scored 1300 points in the LMSYS Chatbot Arena benchmark, which is above both ChatGPT-4o at 1286 and Anthropic’s Claude-3 at 1271. The previous Gemini 1.5 Pro model had scored a total of 1261 thus making this an impressive improvement.
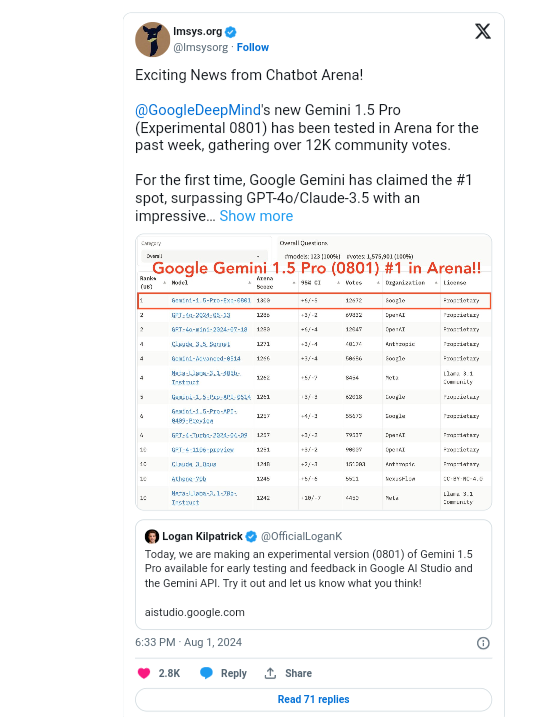
Moreover, the introduction of Gemini 1.5 Pro has sparked enormous interest in the AI community.
Early feedback from its users on social media suggests that the new model is currently doing very well, with some noting that it outperforms ChatGPT-4o.
This reflects a growing competition in the AI market, providing users with more advanced options to choose from.Although Gemini 1.5 Pro has achieved high scores, it is still in the experimental phase.
This means that the model may undergo further changes before it becomes widely available. As of now, it is uncertain whether this version will become the standard model going forward.
However, its current performance marks an important development in AI technology and highlights the ongoing advancements in the field.
About The Author
Related posts:
 Ubwenge bukorano (AI): Ni iki? Bukora gute? Bufasha iki? Ni izihe mpungenge buteje?
Ubwenge bukorano (AI): Ni iki? Bukora gute? Bufasha iki? Ni izihe mpungenge buteje?
 What is generative AI and why is it so popular? Here’s everything you need to know
What is generative AI and why is it so popular? Here’s everything you need to know
 Abakoresha ChatGPT y’ubuntu bemerewe gusaba amafoto
Abakoresha ChatGPT y’ubuntu bemerewe gusaba amafoto
 Udushya Iphone 16 izanye: Amaso azasimbura intoki, Siri nshya na Genmoji izagufasha kwikorera ’emojis’ zihariye
Udushya Iphone 16 izanye: Amaso azasimbura intoki, Siri nshya na Genmoji izagufasha kwikorera ’emojis’ zihariye

